Anthropic acaba de lanzar Claude Opus 4.8, su modelo insignia más reciente, y los números hablan por sí solos.
En solo seis semanas, desde la versión 4.7, el equipo logró avances concretos en benchmarks técnicos, opciones de control de razonamiento y herramientas de orquestación de agentes, todo sin tocar el precio.
En este artículo veremos qué trae de nuevo Opus 4.8, cómo se compara frente a GPT-5.5 y Gemini en pruebas de código real, qué son los flujos de trabajo dinámicos en Claude Code y por qué la brecha de precios con modelos chinos como DeepSeek sigue siendo el elefante en la sala.
¿Qué es Claude Opus 4.8 y qué lo diferencia de Opus 4.7?
Claude Opus 4.8 es la última versión del modelo más potente de la familia Claude. Se sitúa por encima de Sonnet y Haiku en capacidad, y está pensado para tareas que exigen razonamiento complejo, programación avanzada y flujos de trabajo autónomos de múltiples pasos.
Construido directamente sobre Opus 4.7, este lanzamiento no es un salto de generación: es una iteración rápida y deliberada. La arquitectura actualizada se construye sobre los cimientos de la versión anterior, con mejoras de rendimiento en los principales indicadores técnicos.
Benchmarks Clave: ¿Cómo Rinde Opus 4.8 Frente a la Competencia?
SWE-bench Pro: El Test que Más Importa en Coding
Para desarrolladores, SWE-bench Pro es el indicador más relevante. Evalúa si la IA puede resolver problemas difíciles de ingeniería de software extraídos de bases de código reales de producción, en múltiples lenguajes.
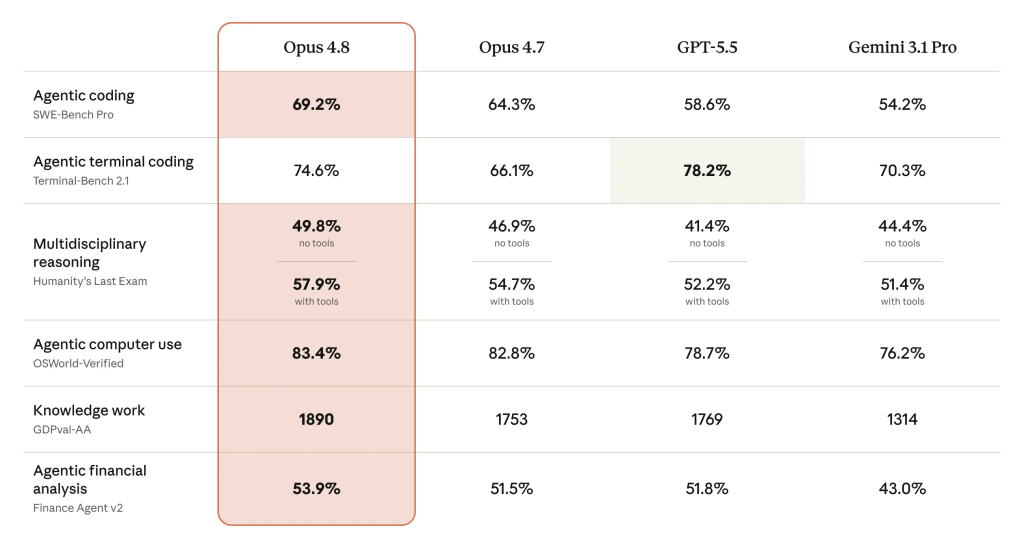
En esa prueba, Opus 4.8 alcanzó el 69,2%, frente al 64,3% de Opus 4.7. GPT-5.5 de OpenAI obtuvo un 58,6%, y el Gemini 3.1 Pro de Google quedó con un 54,2%. Una diferencia de más de 10 puntos porcentuales sobre los modelos de OpenAI y Google, sin cambio de precio, es un argumento técnico difícil de ignorar.
Humanity’s Last Exam y uso real del sistema operativo
En Humanity’s Last Exam, que evalúa preguntas de nivel experto en decenas de disciplinas académicas, Opus 4.8 alcanzó el 49,8% sin herramientas y el 57,9% con ellas, superando a sus tres rivales.
En OSWorld-Verified, que mide tareas de uso real del ordenador como navegar por interfaces de software, obtuvo un 83,4%, superando levemente el 82,8% de Opus 4.7.
Terminal-Bench 2.1: La única derrota
La única derrota fue en Terminal-Bench 2.1, que mide el rendimiento en tareas de línea de comandos. GPT-5.5 lidera con un 78,2%, mientras que Opus 4.8 obtuvo un 74,6%. Mejor que Gemini y que Opus 4.7, pero segundo puesto frente a OpenAI en este benchmark específico.
Control de esfuerzo: Cinco niveles de razonamiento configurables
Una de las novedades más prácticas para desarrolladores es el control de esfuerzo. Ahora puedes decirle explícitamente al modelo cuánto debe pensar antes de responder.
Anthropic permite a los usuarios controlar con qué intensidad razona el modelo. «Alta» es la configuración predeterminada y gestiona bien la mayoría de las tareas, mientras que «Extra» —denominada «xhigh» dentro de Claude Code— dedica más cómputo a problemas más difíciles. «Máx» es el nivel más profundo. «Baja» y «Media» destinan menos tokens a la misma tarea, ahorrando tiempo a cambio de precisión.
Esto tiene implicaciones directas en costos. Si estás construyendo un pipeline de CI/CD donde la mayoría de las llamadas son verificaciones simples, usar nivel «Bajo» puede reducir el consumo de tokens de forma significativa. Para migraciones complejas de bases de código o análisis de arquitectura, «Máx» justifica el gasto adicional.
El control de esfuerzo aparece junto al selector de modelos en Claude.ai y Cowork, disponible en todos los planes.

Riesgos de sistemas como ChatGPT
Antes de integrar modelos de IA como Claude Opus 4.8 en producción, conoce los riesgos reales que presentan estos sistemas y cómo mitigarlos en tu stack tecnológico.
Flujos de trabajo dinámicos en Claude Code: Orquestación de subagentes
Este es el feature más relevante para equipos de ingeniería que trabajan con agentes autónomos.
Para la ingeniería empresarial a gran escala, Anthropic introduce una vista previa de investigación de flujos de trabajo dinámicos dentro de Claude Code. Esta función permite al sistema coordinar cientos de subagentes en paralelo para ejecutar migraciones masivas de bases de código de forma fluida.
En términos prácticos: Claude puede escribir sus propios scripts de orquestación, lanzar subagentes en paralelo dentro de una misma sesión, verificar sus resultados y consolidar el output. No es solo un modelo que ejecuta código; es un sistema que puede coordinar trabajo distribuido.
Honestidad y alineación: El argumento de seguridad para producción
Anthropic no compite solo en benchmarks técnicos; también apuesta fuerte por la fiabilidad del modelo en entornos sensibles.
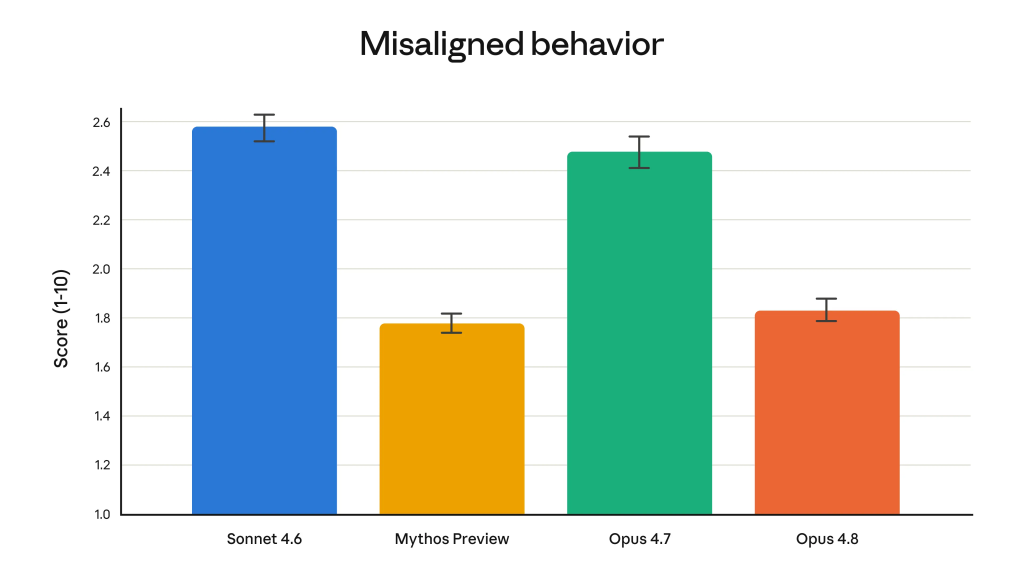
Opus 4.8 tiende a señalar de forma activa los problemas o las limitaciones de sus propios análisis. Además, tiene cuatro veces menos probabilidades que su predecesor de permitir que pasen desapercibidos fallos en el código o de emitir alucinaciones en sus respuestas.
El equipo de alineación de Anthropic indicó que Opus 4.8 alcanza nuevos máximos en métricas de rasgos prosociales, como apoyar la autonomía del usuario y actuar en su mejor interés.
Precios: $5/$25 vs. DeepSeek a $0.87 por Millón de Tokens
Aquí está la conversación más incómoda del ecosistema.
El precio no cambió: sigue siendo $5 por millón de tokens de entrada y $25 por millón de tokens de salida. También hay un modo rápido que ejecuta el mismo modelo a 2,5 veces la velocidad por $10 de entrada y $50 de salida por millón.
DeepSeek V4 Pro hizo permanente su descuento del 75% la semana pasada: $0,435 por millón de tokens de entrada y $0,87 por millón de tokens de salida. El modo rápido de Anthropic cuesta aproximadamente 57 veces más por token de salida que DeepSeek V4 Pro.
La respuesta de Anthropic a esta brecha es calidad y seguridad verificable. En SWE-bench Pro, Opus 4.8 supera a los dos modelos chinos. En alineación, ninguno se acerca a los benchmarks publicados por Anthropic.
Para uso intensivo en producción, la decisión depende del caso: aplicaciones con requerimientos estrictos de compliance o confiabilidad justifican el costo de Anthropic. Para prototipos, herramientas internas o volúmenes masivos donde el costo es el factor crítico, DeepSeek es difícil de ignorar.

Devin: El primer ingeniero de software IA
Claude Opus 4.8 no es el único agente que promete revolucionar el desarrollo. Descubre cómo Devin cambió la conversación sobre la IA como compañero de programación.
¿Cuándo conviene usar Claude Opus 4.8?
Basándonos en las capacidades del modelo, estos son los escenarios donde Opus 4.8 aporta más valor:
- Migraciones masivas de código: Los flujos de trabajo dinámicos con subagentes en paralelo reducen el tiempo de ejecución en tareas que antes requerían coordinación manual.
- Pipelines con verificación crítica: La menor tasa de alucinaciones y la tendencia a señalar sus propias limitaciones lo hacen más confiable en sistemas donde los errores silenciosos tienen consecuencias reales.
- Tareas de razonamiento complejo: El control de esfuerzo permite afinar cuánto computa el modelo, balanceando costo y precisión según la tarea.
Un salto incremental con implicaciones reales
Claude Opus 4.8 no reinventa el paradigma; lo mejora con precisión quirúrgica. Mejor rendimiento en coding, control de esfuerzo configurable, orquestación de subagentes y mejoras verificables en honestidad, todo al mismo precio que su predecesor.
La brecha con DeepSeek en costos sigue siendo un factor determinante para muchos equipos. Pero para los que ya trabajaban con Opus 4.7 y construyen sistemas donde la confiabilidad y la alineación importan, la actualización es gratuita y sustancial.

SEO estratega y redactor de contenidos especializado en temas de tecnología. Experto en crear estrategias de contenido que comunican complejidad técnica de forma clara y accesible.