¿Estás buscando una IA que realmente pueda asumir tus proyectos más exigentes sin perder el hilo a mitad del camino? Eso es exactamente lo que Anthropic prometió, y lo que Claude Opus 4.7 llega a cumplir.
En este artículo te contamos qué trae este nuevo modelo de Anthropic, en qué supera a su versión anterior, cómo se compara frente a GPT-5.4 y Gemini 3.1, y si realmente vale la pena adoptarlo en tu stack de trabajo.
¿Qué es Claude Opus 4.7 y por qué importa ahora?
Anthropic presentó oficialmente Claude Opus 4.7 el 16 de abril de 2026, y desde el primer momento quedó claro que el enfoque no es simplemente mejorar respuestas de chat.

El modelo está diseñado para manejar tareas largas y complejas con mayor precisión y menor supervisión, algo que los equipos de desarrollo de software y sectores como el del análisis financiero venían pidiendo desde hace tiempo.
Opus 4.7 is a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks. Users report being able to hand off their hardest coding work—the kind that previously needed close supervision—to Opus 4.7 with confidence. Opus 4.7 handles complex, long-running tasks with rigor and consistency, pays precise attention to instructions, and devises ways to verify its own outputs before reporting back.
https://www.anthropic.com/news/claude-opus-4-7
La diferencia más notable frente a versiones anteriores es su capacidad de actuar de forma autónoma.
Las métricas publicadas por Anthropic muestran que el modelo está ganando terreno de forma significativa en flujos de trabajo autónomos, lo que lo posiciona como una herramienta orientada a producción real, no solo a pruebas de laboratorio.
Rendimiento: los números que respaldan el salto
Los benchmarks son el lenguaje de los profesionales tech, y Claude Opus 4.7 tiene mucho que decir.
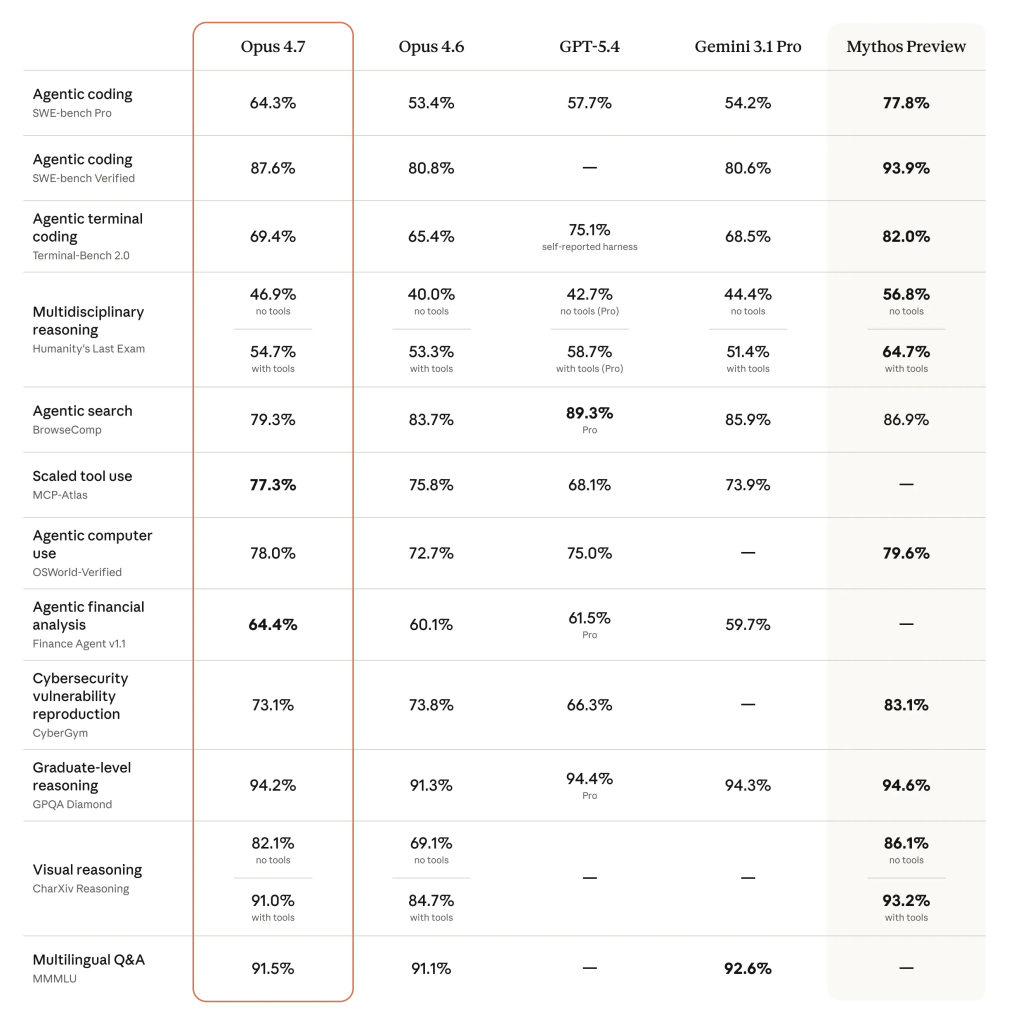
Codificación avanzada
En la prueba SWE-bench Verified, el nuevo modelo alcanzó el 87,6 %, frente al 80,8 % registrado en la versión 4.6. Ese salto no es menor: se traduce en que el modelo puede resolver tareas de ingeniería de software que antes requerían revisión humana constante.
Anthropic lanzó Claude Opus 4.7 con mejoras en programación (80,5% en SWE-bench) y razonamiento de documentos (80,6% vs 57,1% de la versión anterior), superando a GPT-5.4 en evaluaciones clave.
Finanzas y razonamiento complejo
Para los equipos de análisis financiero, el salto es aún más relevante. El modelo alcanzó una puntuación de 0,813 en el módulo de Finanzas Generales, un avance significativo respecto a la puntuación de 0,767 de la versión anterior.
Opus 4.7 obtuvo puntuaciones más altas que su predecesor en evaluaciones que incluyen agentes financieros y GDPval-AA, que mide el trabajo de conocimiento económicamente valioso en los ámbitos financiero y legal.
Coherencia en tareas largas
En Vending-Bench 2, el rendimiento se evalúa por el saldo final tras una simulación prolongada; en un caso, el modelo alcanzó $10.937, superando los $8.018 obtenidos por Claude Opus 4.6, lo que sugiere mayor coherencia operativa en tareas autónomas de largo plazo.
Novedades técnicas clave del nuevo Claude
Visión de alta resolución
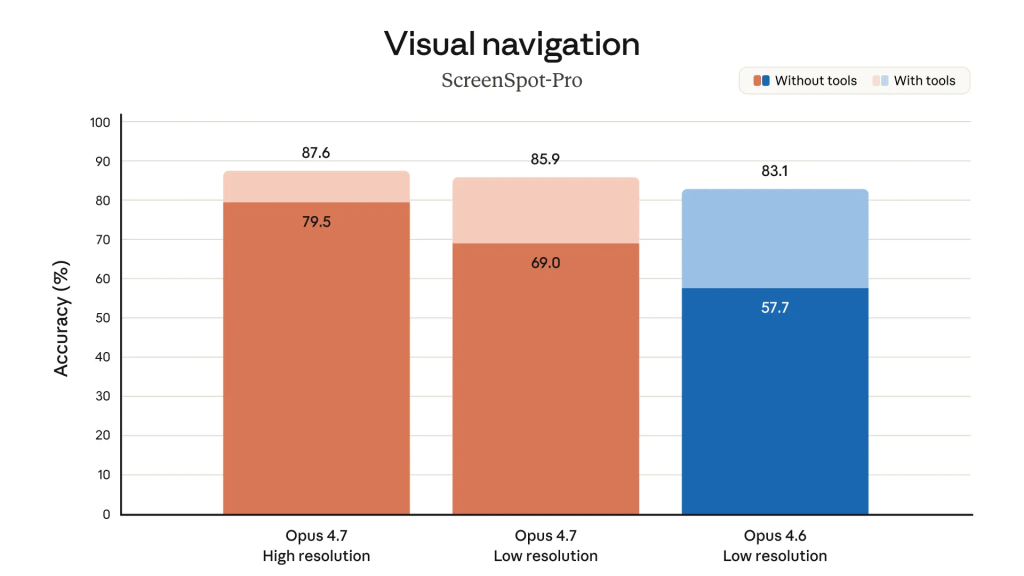
Una de las actualizaciones más tangibles para quienes trabajan con datos visuales: Opus 4.7 procesa imágenes en resoluciones de hasta 2.576 píxeles en el borde largo, más de tres veces la capacidad de los modelos Claude anteriores.
Esto significa que el modelo puede interpretar con precisión gráficas de datos complejas, interfaces de usuario detalladas y diagramas técnicos sin perder contexto visual.
Nivel de esfuerzo «xhigh» y presupuestos de tareas
La actualización trae un nuevo nivel de esfuerzo de razonamiento «xhigh», que permite a los desarrolladores controlar mejor el equilibrio entre velocidad y profundidad de cálculo. Una función beta, presupuestos de tareas, permite a las empresas gestionar el uso de tokens en operaciones de IA extendidas.
Autovalidación de respuestas
Según Anthropic, el modelo «verifica sus propias respuestas antes de responder», lo que mejora la fiabilidad en trabajos críticos como la ingeniería de software y el modelado de datos.
/ultrareview en Claude Code
En Claude Code, un nuevo comando /ultrareview realiza revisiones de código automáticas profundas, detectando problemas como lo haría un ingeniero sénior humano.
Claude Opus 4.7 vs la competencia
Una pregunta legítima para cualquier profesional tech: ¿compensa frente a GPT-5.4 o Gemini 3.1 Pro?
Anthropic informó que Opus 4.7 superó al GPT-5.4 de OpenAI y al Gemini 3.1 Pro de Google en pruebas de uso de herramientas e interacción con el ordenador.
No es una ventaja aplastante en todos los frentes, pero sí es una señal de que el nuevo modelo de Anthropic ocupa un lugar competitivo en las categorías que más importan a los equipos técnicos: autonomía, razonamiento estructurado y manejo de contextos largos.
Opus 4.7 utiliza un tokenizador actualizado que mejora la eficiencia en el procesamiento de texto, aunque puede incrementar el conteo de tokens de ciertas entradas entre 1,0 y 1,35 veces. Esto es relevante para gestionar costos en proyectos de alto volumen.
Seguridad y ciberseguridad: un enfoque deliberado
Anthropic tomó una decisión consciente en este lanzamiento. Opus 4.7 se lanza con salvaguardas automáticas que detectan y bloquean solicitudes prohibidas o de alto riesgo en materia de ciberseguridad.
Anthropic destacó que Opus 4.7 mantiene un perfil de seguridad similar al de Opus 4.6, con mejor resistencia ante ataques de inyección de prompts y respuestas engañosas en pruebas internas.
Un nuevo Programa de Verificación Cibernética permitirá a profesionales de la seguridad probar el modelo en entornos controlados para análisis de penetración y búsqueda de vulnerabilidades.
Disponibilidad y precios
Buenas noticias para quienes ya usan la plataforma de Anthropic: el precio no cambia.
Opus 4.7 está disponible en Claude.ai, la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry. Los precios no cambian respecto a la versión 4.6.
Lo que debes tener en cuenta antes de migrar
Claude Opus 4.7 trae mejoras reales, pero hay un factor que no puedes ignorar: el consumo de tokens.
El modelo consume significativamente más tokens que su predecesor, agotando cuotas completas en sesiones de programación.
Antes de migrar en producción, evalúa el tipo de tareas que ejecutas. Para proyectos de codificación autónoma, análisis financiero y razonamiento complejo, la ganancia en calidad probablemente justifica el costo. Para tareas más simples o de alta frecuencia, quizás valga la pena mantener un modelo más ligero en esos flujos.
Preguntas frecuentes sobre Claude Opus 4.7
¿En qué se diferencia Claude Opus 4.7 de la versión 4.6?
Mejoras en codificación (87,6% vs 80,8% en SWE-bench), mayor resolución visual (3x), nuevo nivel de razonamiento «xhigh» y autovalidación de respuestas.
¿Cuánto cuesta Claude Opus 4.7?
El precio se mantiene igual: $5 por millón de tokens de entrada y $25 por millón de tokens de salida.
¿Dónde está disponible el nuevo modelo de Anthropic?
En Claude.ai, la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry.
¿Es mejor que GPT-5.4?
En pruebas de uso de herramientas, codificación compleja e interacción con computadora, Opus 4.7 supera a GPT-5.4 según los benchmarks publicados por Anthropic.
¿Consume más tokens que la versión anterior?
Sí. Puede utilizar entre 1,0 y 1,35 veces más tokens dependiendo del tipo de contenido, lo que hay que considerar en proyectos de alto volumen.
Si tu equipo trabaja con tareas de software complejas, análisis de datos o flujos de trabajo autónomos, Claude Opus 4.7 es una actualización que merece evaluarse en producción.
En Grupo Apok trabajamos con las herramientas de IA más avanzadas del mercado para diseñar soluciones que realmente escalan. Si quieres integrar modelos como este en tus procesos de negocio, conoce nuestros servicios aquí.

SEO estratega y redactor de contenidos especializado en temas de tecnología. Experto en crear estrategias de contenido que comunican complejidad técnica de forma clara y accesible.